Comparing Simple Exploration Techniques: ε-Greedy, Annealing, and UCB
Following on from the previous experiment with ε-Greedy methods, the next question is, can we explore more intelligently?
The answer is yes, and you can read more about it in the book. But in essence, bandits generally use three forms of exploration. Standard ε-Greedy, which randomly chooses an action some proportion of the time, and annealing version, which reduces the exploration over time, and finally UCB, which chooses an action depending on how often the action has been sampled.
The Testing Environment
I will reuse the environment from the previous ε-Greedy experiment. See that workshop for more details.
!pip install banditsbook==0.1.1 pandas==1.1.2 matplotlib==3.3.2 &2> /dev/null
from arms.bernoulli import BernoulliArm
# Define two adverts, with a probability of clicking from the users
# This is a simulation. Imagine that these are real ads.
arm0 = BernoulliArm(0.05)
arm1 = BernoulliArm(0.4)
arms = [arm0, arm1]
Running the Experiment
The code below will compare the three algorithms on the simulated environment.
from arms.bernoulli import BernoulliArm
from testing_framework.tests import test_algorithm
from algorithms.epsilon_greedy.standard import EpsilonGreedy
from algorithms.softmax.annealing import AnnealingSoftmax
from algorithms.ucb.ucb1 import UCB1
import pandas as pd
import random
random.seed(42)
num_sims = 1000 # Repetitions
horizon = 250 # Number of steps in experiment
n_arms = len(arms)
algo1 = AnnealingSoftmax([], []) # Annealing ε-Greedy
algo1.initialize(n_arms)
algo2 = EpsilonGreedy(0.05, [], []) # Standard ε-Greedy, exploring 5% of the time
algo3 = UCB1([], []) # UCB
algo3.initialize(n_arms)
algos = [("e_greedy", algo2), ("annealing_softmax", algo1), ("ucb", algo3)]
# A bit of code to loop over each algorithm and average the results
df = pd.DataFrame()
for algo in algos:
sim_nums, times, chosen_arms, rewards, cumulative_rewards = test_algorithm(
algo[1], arms, num_sims, horizon)
arrays = [sim_nums, times]
index = pd.MultiIndex.from_arrays(
arrays, names=('simulation', 'time'))
df_chosen_arm = pd.DataFrame(chosen_arms, index=index, columns=[algo[0]])
df_probability_selected = df_chosen_arm.groupby(level=1).sum() / num_sims
df = pd.concat([df, df_probability_selected], axis=1)
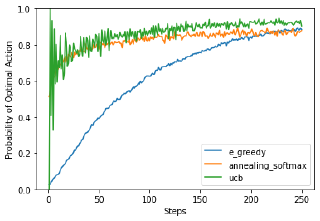
df.plot(ylim=[0,1],ylabel="Probability of Optimal Action",xlabel="Steps");
You can see that the ε-Greedy algorithm is taking a long time to converge to a similar level of performance. The reason being that it is still spending a large proportion of the time chossing random actions.
The annealing version rapidly reduces the amount of random exploration to speed this learning up. This is better, but you need to tune the hyper-parameters (initial exploration rate, final exploration rate and how fast to anneal) for your specific problem.
UCB attempts to quantify the number of times that action/state has been explored. If it has been explored a lot, and it is not the best action, then there’s little point in exploring more. This is good because there are no hyper-parameters but you’ll need to store a representation UCB attempts to quantify the number of times that action/state has been explored. If it has been explored a lot, and it is not the best action, then there’s little point in exploring more. This is good because there are no hyper-parameters but you’ll need to store visitation counts; something that might not be possible for certain problems.