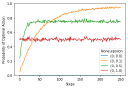
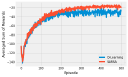
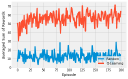
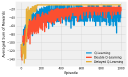
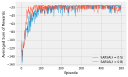
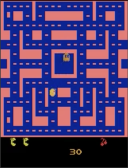
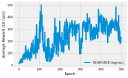
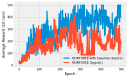
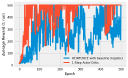
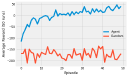
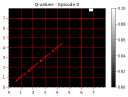
If you have read through (or are still reading!) the book, you’ve probably asked “where’s the code!” I actively decided to leave all code out of the book, to leave more room for explanation and content. You can use this page to find code for all of the examples that I present in the book.
Browse through the chapter headings below to find the page or repository that I talk about in the main text.