
Reacher is an old Gym environment that simulates an arm that is asked to reach for a coordinate. In this example I have created a simplified real-life version of this environment using servo motors and used PPO to train a policy.

There’s a bit too much code to go in a notebook, so I have decided to present this example as a walk-through instead. All of the code is located in a separate repository.
Professional Help
If you’re doing something like this in your business, then please reach out to https://winder.ai. Our experts can provide no-nonsense help that I guarantee will save you time.
The Easy Route: Simulation
So nobody is left out, I created a simple simulation of the hardware so you can run the experiment without any electronics.
Installation
I used stable_baselines 2 for the PPO implementation, which unfortunately means you have to use Tensorflow 1.5, which means you have to use Python 3.7. Install the project by cloning the repository and using poetry to install the dependencies.
- git clone https://gitlab.com/winderresearch/rl/projects/real-life-reacher
- cd real-life-reacher && poetry install
Training
Train the agent by instantiating the environment with the simulated controller.
python ppo_policy.py --total_timesteps=1025 --plot_policy --monitoring_dir=./monitoring --seed=42 --model_path trained_policies/ppo_RealLifeReacher-v0_sim.zip
This will load the PPO hyperparameters train the agent, store the results in the ./monitoring directory and save the trained parameters trained_policies/ppo_RealLifeReacher-v0_sim.zip.
Evaluation
You can then reuse the policy and/or re-evaluate it again with:
python ppo_policy.py trained_policies/ppo_RealLifeReacher-v0_sim.zip --total_timesteps=1025 --plot_policy --monitoring_dir=./monitoring --seed=42
This will spit out an interesting plot that shows you the policy. This is only possible because of small state/action space.
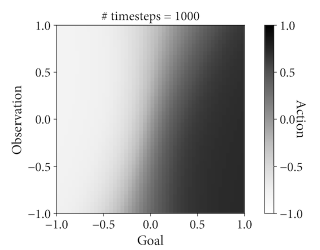
The y-axis shows the observation from the (simulated) servo feedback. The x-axis shows the goal selected by the environment. The shaded area is the policy for each goal-observation position; the action. Light values are negative, dark values are positive.
In this super simple scenario, you would expect that there should be a gradient going from left to right, because the goal corresponds exactly to the action. If you tell it to move to -0.5, the action should aways be -0.5.
But interestingly you can see that there is often a subtle slope. I think this is purely due to the policy model used by PPO. The model is over determined for the complexity of the problem. I suspect that with further tweaking of the various hyper-parameters you could get it to converge.
Hyper-Parameter Tuning
For hyper-parameter tuning I used the optuna library. You can see the code in the repository if you’re interested.
Real Life!
Now for the interesting part. It is easy to extend this into the real world thanks to the controller interface. But you will need some hardware.
- 1x LX-16A servo motors
- 1x BusLinker V2.4 serial servo driver board
- An extra power supply to power the motors via the driver board
- A USB cable
You should be able to find these on Amazon or in your favourite online store.
The code for the real life controller converts the requests from the +/- 1 to commands that the servo can understand. There’s also a bit of code to prevent episodes going on for too long. Sometimes the agent got itself stuck due to some unlucky parameters.
The reset mechanism is interesting too. I chose to randomly reset the controller to any position, not to a fixed position. That way the agent is able to generalize to any position.
Training and Evaluation
The instructions/code is exactly the same as before, except for the addition of a --for_real flag.
So for example, to train a new policy you would run:
python ppo_policy.py --total_timesteps=1025 --plot_policy --monitoring_dir=./monitoring --seed=42 --model_path trained_policies/ppo_RealLifeReacher-v0_sim.zip --for_real
And to evaluate and/or reuse an trained policy you would run:
python ppo_policy.py trained_policies/ppo_RealLifeReacher-v0_real.zip --total_timesteps=1025 --plot_policy --monitoring_dir=./monitoring --seed=42 --for_real
Future Work
Cool eh! Obviously this is ridiculously simple in the grand scheme of things. You could imagine a much more complex arm, where the challenge is to pick up an object from any position or draw a picture or play a tune. Anything you can think of.
And in an industrial project you need to think about all the other elements, operational deployment, safety, robustness, etc. That’s a much bigger project. If you’re doing something like this in your business, then please reach out to https://winder.ai. Our experts can provide no-nonsense help that I guarantee will save you time.