Real Life Reacher with the PPO Algorithm
Oct 2020
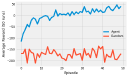
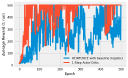
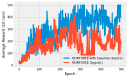
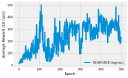
Reacher is an old Gym environment that simulates an arm that is asked to reach for a coordinate. In this example I have created a simplified real-life version of this environment using servo motors and used PPO to train a policy. There’s a bit too much code to go in a notebook, so I have decided to present this example as a walk-through instead. All of the code is located in a separate repository.