Eligibility Traces
Phil Winder, Oct 2020
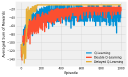
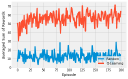
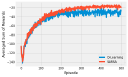
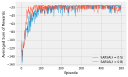
Eligibility traces implement n-Step methods on a sliding scale. They smoothly vary the amount that the return is projected, from a single step up to far into the future. They are implemented with tracers which remember where the agent has been in the past and update them accordingly. They are intuitive, especially in a discrete setting.